|

Trois tiers (architecture)
Organisation
informatique en trois niveaux, les données, les
applications de gestion des données et enfin les
applications clients, contrairement à l’architecture
standard ne comprenant que deux niveaux.
Larchitecture trois
tiers
Les limites de
l'architecture deux tiers proviennent en grande partie
de la nature du client utilisé :
-
le frontal est complexe et non standard (même s'il
s'agit presque toujours d'un PC sous Windows),
-
le middleware entre client et serveur n'est pas
standard.
La solution résiderait
donc dans l'utilisation d'un poste client simple
communicant avec le serveur par le biais d'un protocole
standard.
Dans ce but,
l'architecture trois tiers applique les principes
suivants :
-
les données sont toujours gérées de façon
centralisée,
-
la présentation est toujours prise en charge par le
poste client,
-
la logique applicative est prise en charge par un
serveur intermédiaire.
Les premières
tentatives de mise en oeuvre d'architecture trois tiers
proposaient l'introduction d'un serveur d'application
centralisé exploité par les postes clients à l'aide
dialogue RPC propriétaire.
Les mécanismes
nécessaires à la mise en place de telles solutions
existent depuis longtemps :
-
UNIX propose un mécanisme de RPC intégré au système
NFS,
-
DDE, puis DCOM de Microsoft permettent
l'instauration d'un dialogue RPC entre client et
serveur,
-
certains environnements de développement facilitent
la répartition des traitements entre le poste client
et le serveur,
-
des solutions propriétaires comme ForT ou Implicite
permettent l'exploitation d'un serveur d'application
par des clients simplement équipés d'un
environnement d'exécution (runtime).
Cependant,
l'application de ces technologies dans une architecture
trois tiers est complexe et demande des compétences très
pointues, du fait du manque de standards. Malgré ses
avantages techniques évidents, ce type d'application fut
souvent jugé trop coûteux à mettre en place.
Ce premier essai s'est
soldé par un échec dû en grande partie à l'absence de
standard et à la complexité des mécanismes mis en
oeuvre.
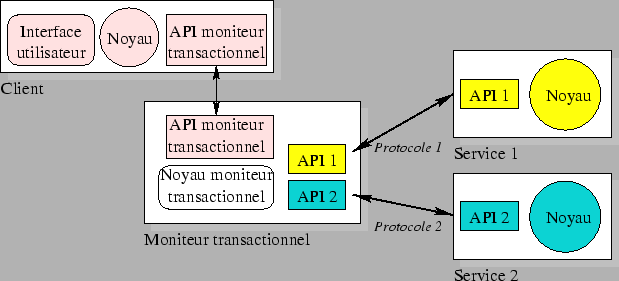
Ce
type de serveur héberge un moniteur transactionnel qui
s'occupe de la mise en relation du client avec un
ensemble de serveurs de données. Le serveur
transactionnel, interrogé en utilisant une API unique,
masque au client la complexité de l'organisation des
serveurs de données.
|
 |
|
Figure
6.1: Fonctionnement d'un moniteur
transactionnel |
Le moniteur
transactionnel permet de garantir que toutes les
transactions vérifient la règle ACID :
-
Atomicité : La transaction ne peut être
partiellement effectuée,
-
Cohérence : Une transaction fait passer la
base d'un état cohérent à un autre,
-
Isolation : Une transaction n'est pas
affectée par le résultat des autres transactions,
-
Durée : Les modifications dues à une
transaction sont durablement garanties.
En fait, soit une
transaction a définitivement eu lieu, soit elle n'a
jamais existé.
La notion de serveur
transactionnel est citée brièvement ici car elle
correspond, à mon avis, à une architecture trois tiers
puisqu'une partie des traitements applicatifs est
centralisée.
S'il
est un phénomène qui a marqué le monde de l'informatique
ces dernières années, c'est bien celui d'Inter.
Ce réseau mondial, créé
en 1969 par l'armée américaine, puis utilisé par les
chercheurs et autres scientifiques, a connu une
croissance phénoménale auprès du grand public avec
l'introduction du World Wide Web en 1989. Ce
dernier permet de publier simplement des informations
richement mises en forme et pouvant même, par la suite,
contenir des données multimédia.
La véritable révolution
du WWW réside dans son caractère universel, rendu
possible par l'utilisation de standards reconnus.
L'universalité du Web
repose sur des standards simples et admis par tous :
-
HTML, pour la description des pages disponibles sur
le Web,
-
HTTP, pour la communication entre navigateur et
serveur Web,
-
TCP/IP, le protocole réseau largement utilisé par
les systèmes Unix,
-
CGI, l'interface qui permet de déclencher à distance
des traitements sur les serveurs Web.
HTML (HyperText Markup Langage)
HTML est le langage de
description de pages hypertexte utilisé par le World
Wide Web, il est issu de SGML.
Une page HTML est
composée de son contenu propre (du texte plus ou moins
richement mis en forme) et de références statiques vers
d'autres sources d'informations (images, liens vers
d'autres documents... ).
La consultation d'une
page HTML n'implique donc que très rarement le
chargement du seul fichier décrivant la page, il
s'accompagne en général de celui de nombreux fichiers
annexes. Ces chargements mettent en oeuvre le protocole
HTTP.
HTTP est un protocole
réseau applicatif (dernier niveau du modèle OSI) sans
connexion utilisé pour l'échange des données sur le Web.
En fait, une connexion HTTP est créée pour chaque
requête et ne dure que pendant l'exécution de cette
dernière.
|
 |
|
Figure
6.2: Le fonctionnement de base de
HTTP |
Le protocole HTTP, en
temps que protocole réseau applicatif, s'appuie sur un
protocole de transport indépendant qui, dans le cadre
d'Inter, est TCP/IP
TCP/IP (Transmission Control Protocol / Inter
Protocol)
TCP/IP est un protocole
réseau de niveau trois et quatre (réseau et transport)
qui s'est largement imposé sur les systèmes Unix, puis
sur Inter, et fait aujourd'hui figure de standard
universel.
Si le fonctionnement de
TCP/IP s'adapte bien à la topologie et à la qualité de
service du réseau Inter, on ne peut en dire autant du
mariage avec le protocole HTTP. En effet, TCP/IP utilise
un mécanisme de ``démarrage lent'' afin d'éviter les
engorgements du réseau. Ce mécanisme permet à la machine
émettrice d'ouvrir progressivement une fenêtre de
congestion en doublant le nombre de paquets émis à
chaque aller-retour. En général, la courte durée des
échanges HTTP ne permet pas à la fenêtre de congestion
d'atteindre la largeur de bande fournie par le réseau
local .
CGI est un standard
permettant d'écrire des extensions compatibles avec la
grande majorité des serveurs HTTP. Ces extensions
permettent l'exécution d'une action par le serveur à la
demande d'un client.
Ce mécanisme
relativement simple, voire même rustique, entraîne
l'exécution d'un processus propre à chaque invocation,
ce qui est très consommateur de ressources.
De ce fait, des
extensions comme ISAPI, NSAPI ou les servlets Java sont
souvent préférés au standard CGI.
Aucun des mécanismes
mis en oeuvre par Inter n'est exempt de défaut et il
est relativement simple de trouver plus performant. En
fait, la force de l'ensemble repose essentiellement dans
son universalité.
La notion d'Intra
est née de l'intégration des principes d'Inter et des
technologies déployées dans l'entreprise :
-
on utilise le réseau local de l'entreprise,
-
les données sont toujours gérées par un SGBD,
-
les mécanismes utilisés pour interroger le SGBD sont
toujours les mêmes.
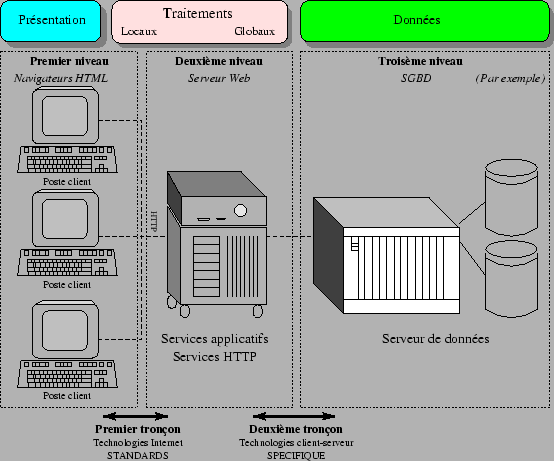
L'architecture trois
tiers, encore appelée client-serveur de deuxième
génération ou client-serveur distribué, sépare
l'application en trois niveaux de service distincts :
-
premier niveau : l'affichage et les
traitements locaux (contrôles de saisie, mise en
forme de données... ) sont pris en charge par le
poste client,
-
deuxième niveau : les traitements applicatifs
globaux sont pris en charge par le service
applicatif,
-
troisième niveau : les services de base de
données sont pris en charge par un SGBD.
|
 |
|
Figure
6.3: Le découpage d'une application
en pavés fonctionnels indépendants |
Tous ces niveaux étant
indépendants, ils peuvent être implantés sur des
machines différentes, de ce fait :
-
le poste client ne supporte plus l'ensemble des
traitements, il est moins sollicité et peut être
moins évolué, donc moins coûteux,
-
les resources présentes sur le réseau sont mieux
exploitées, puisque les traitements applicatifs
peuvent être partagés ou regroupés (le serveur
d'application peut s'exécuter sur la même machine
que le SGBD),
-
la fiabilité et les performances de certains
traitements se trouvent améliorées par leur
centralisation,
-
il est relativement simple de faire face à une forte
montée en charge, en renforçant le service
applicatif.
Dans le cadre d'un
Intra, le poste client prend la forme d'un simple
navigateur Web, le service applicatif est assuré par un
serveur HTTP et la communication avec le SGBD met en
oeuvre les mécanismes bien connus des applications
client-serveur de la première génération.
Ce type d'architecture
fait une distinction te entre deux tronçons de
communication indépendants et délimités par le serveur
HTTP :
-
le premier tronçon relie le poste client au serveur
Web pour permettre l'interaction avec l'utilisateur
et la visualisation des résultats. On l'appelle
circuit froid et n'est composé que de standards
(principalement HTML et HTTP). Le serveur Web tient
le rôle de ``façade HTTP'',
-
le deuxième tronçon permet la collecte des données,
il est aussi appelé circuit chaud. Les
mécanismes utilisés sont comparables à ceux mis en
oeuvre pour une application deux tiers. Ils ne
franchissent jamais la façade HTTP et, de ce fait,
peuvent évoluer sans impacter la configuration des
postes clients.
|
 |
|
Figure
6.4: Répartition des couches
applicatives dans une architecture trois
tiers |
Dans
l'architecture trois tiers, le poste client est
communément appelé client léger ou Thin Client,
par opposition au client lourd des architectures deux
tiers. Il ne prend en charge que la présentation de
l'application avec, éventuellement, une partie de
logique applicative permettant une vérification
immédiate de la saisie et la mise en forme des données.
Il est souvent constitué d'un simple navigateur
Inter.
Le poste client ne
communique qu'avec la façade HTTP de l'application et ne
dispose d'aucune connaissance des traitements
applicatifs ou de la structure des données exploitées.
Les évolutions de l'application sont donc possibles sans
nécessiter de modification de la partie cliente.
Par exemple, un
internaute se connectant à www.yahoo.fr pour
effectuer une recherche provoque, sans même le savoir,
l'exécution de traitements sur le serveur. Si ces
traitements évoluent, ce qui doit arriver relativement
souvent, le client continuera à utiliser le service sans
se rendre compte des changements (sauf s'ils lui
apportent de nouveaux services).
De plus, ce même
internaute peut se connecter au serveur en utilisant
tout type de poste client disposant d'un navigateur
compatible HTML (PC sous Windows, Macintosh, Station
Unix, WebPhone... ).
On voit donc ici la
force des architectures trois tiers par rapport au
client-serveur de première génération. Le déploiement
est immédiat, les évolutions peuvent être transparentes
pour l'utilisateur et les caractéristiques du poste
client sont libres.
Les pages HTML, même
avec l'aide de langages de script, sont loin d'atteindre
les possibilités offertes par l'environnement Windows :
-
le multi-fenêtrage n'est pas facile à mettre en
oeuvre,
-
le déroulement de l'application doit se faire
séquentiellement,
-
les pages affichées sont relativement statiques,
-
le développement multi-plateforme peut être
contraignant.
-
l'ergonomie de l'application est limitée aux
possibilités du navigateur.
Pour ces raisons,
certaines applications ne sont pas réalisables dans une
architecture de type Intra (infocentres, applications
bureautiques... ).
Dans les autres cas,
l'appauvrissement de l'interface utilisateur est souvent
le gage d'une plus grande facilité de prise en main de
l'application.
Il est rare en effet de
devoir suivre une formation pour apprendre à se servir
d'un site Web particulier. La plupart du temps, une
formation générale à l'ergonomie des sites Web suffit.
Cette perte de richesse
peut donc se transformer en avantage, à condition de
respecter une charte graphique et ergonomique cohérente
pour toutes les applications Intra d'une entreprise.
Il est possible d'aller
au delà des possibilités offertes par le langage HTML en
y introduisant des applets Java ou des contrôles
ActiveX. Nous ne parlerons pas ici des modules
d'extension du navigateur, encore appelés plug-in,
qui étaient en vogue avant l'arrivée des solutions Java
et ActiveX, car cette solution est trop contraignante à
déployer.
Java est un langage de
développement orienté objet et multi-plateforme
introduit par Sun en 1995. Il s'agit de l'adaptation à
Inter du langage OAK, initialement étudié pour les
environnements de petite taille. Il permet, entre autre,
d'écrire de petites applications, appelées applet,
pouvant être intégrées à des pages HTML pour en enrichir
le contenu.
Le caractère
multi-plateforme de Java se prête bien à une utilisation
sur Inter, où les caractéristiques des postes clients
ne sont pas maîtrisées. Il repose sur l'utilisation d'un
interpréteur de pseudo-code Java, pompeusement appelé
``machine virtuelle''.
Les programmes Java ne
sont pas compilés en code machine, mais en pseudo-code
Java uniquement compréhensible par la machine virtuelle.
Cette dernière interprète le code et se charge de lier
les modules au moment de l'exécution, en les
téléchargeant si nécessaire. La liaison dynamique des
modules au moment de l'exécution permet d'optimiser le
trafic réseau, puisqu'on ne charge que le strict
nécessaire.
Pour ces raisons, un
programme Java s'exécute plus lentement que son
équivalent compilé. La compilation à la volée des
programmes Java et plus encore, la technologie
d'optimisation dynamique de code HotSpot de
Sun, permettent de réduire l'écart de performance avec
des programmes compilés.
Java propose
aujourd'hui une large palette de composants graphiques
et multimédia qui permettent d'atteindre la richesse
fonctionnelle des applications Windows.
Une applet Java est
aussi capable d'exploiter directement un serveur de
données en utilisant JDBC ou de faire appel à des
procédures distantes en utilisant RMI ou CORBA. Nous
verrons ces mécanismes par la suite.
Quand Microsoft entend
parler de ``multi-plateforme'', il comprend
``fonctionnement en dehors de Windows'' et, par
extension directe, ``danger''. De ce fait, il ne pouvait
rester sans réponse devant le phénomène Java.
Après avoir essayé,
sans succès, de confiner Java dans le rôle d'un simple
langage de programmation dépendant de Windows, Microsoft
appuie sa politique Intra sur sa technologie ActiveX.
ActiveX est une
adaptation Inter des composants OCX constituant la
clef de voûte de l'architecture DNA. Les composants
ActiveX exploitent les possibilités de Windows et sont
donc capables d'offrir une grande richesse fonctionnelle
aux applications qui les utilisent.
Ils peuvent être
intégrés à une page HTML mais, à la différence des
applets Java, ils persistent sur le poste client après
utilisation. Ils ne sont alors remplacés que si une
nouvelle version du composant est utilisée. Ce mécanisme
permet d'optimiser les transferts de composants sur le
réseau mais rappelle grandement l'installation locale
d'application, avec ses effets négatifs sur
l'alourdissement du poste client.
Les composants ActiveX
peuvent communiquer entre eux en utilisant la
technologie DCOM ou avec des bases de données, en
utilisant ODBC.
En fait, l'utilisation
des composants ActiveX rend les applications dépendantes
de la plateforme Windows. On se prive alors des
possibilités offertes par d'autres systèmes
d'exploitation ou de postes clients plus simples et
donc, de la possibilité de faire baisser le coût de
possession des postes clients.
En prenant du recul, on
s'aperçoit que l'utilisation d'objets ActiveX dans une
application Intra fait perdre une grande partie de
l'intérêt de cette architecture et rappelle fortement le
client-serveur deux tiers.
Le client léger peut
prendre plusieurs formes :
-
un poste Windows équipé d'un navigateur HTML,
-
une station réseau du type NC. Contrairement à un
simple terminal X, ce type de station prend en
charge des traitements locaux (affichage, contrôle
de saisie, mise en forme de donnée... ). Ce type de
poste client se démarque par un coût de possession
très largement inférieur à celui d'un PC sous
Windows.
-
un terminal Windows (PC) correspondant à un PC
minimal.
Le client léger à
souvent été présenté comme le successeur du PC sous
Windows. En fait, le client léger ne prétend pas
remplacer tous les PC dans l'entreprise, il se présente
plutôt comme une alternative à ce dernier pour certains
besoins particuliers et cohabite très bien avec
l'existant.
Dans une architecture
trois tiers, la logique applicative est prise en charge
par le serveur HTTP. Ce dernier se retrouve dans la
position du poste client d'une application deux tiers et
les échanges avec le serveur de données mettent en
oeuvre les mécanismes déjà vus dans ce type
d'application.
Les développements mis
en oeuvre sur le serveur HTTP doivent être conçus
spécifiquement. Il peuvent mettre en oeuvre :
-
CGI : le mécanisme standard et reconnu de tous, mais
grand consommateur de ressources,
-
NSAPI ou ISAPI : les API de scape et Microsoft
permettant l'écriture d'applications multi-thread
intégrées au serveur HTTP,
-
les scripts serveur comme ASP (Active Server Page
pour IIS) ou PHP (l'équivalent pour Apache) sont
interprétés par le serveur pour générer des pages
dynamiquement,
-
les servlets Java : qui appliquent le mécanisme des
applets aux traitements réalisés sur le serveur.
Comme le protocole HTTP
n'assure pas de gestion d'états, les applications
transactionnelles doivent gérer elles-mêmes le contexte
utilisateur afin de contrôler :
-
le cheminement de l'utilisateur dans l'application,
-
les actions et saisies de l'utilisateur,
-
l'identité de l'utilisateur,
-
la gestion des transactions.
Il existe différentes
méthodes de gestion de contexte :
-
attribution d'un identifiant à chaque étape de la
transaction,
-
stockage de l'ensemble du contexte sur le poste
client.
Ces méthodes
nécessitent le stockage d'informations sur le poste
client :
-
dans un cookie déposé sur le poste client,
-
dans une URL longue,
-
dans des variables cachées au sein de la page HTML.
L'architecture trois
tiers a corrigé les excès du client lourd en
centralisant une grande partie de la logique applicative
sur un serveur HTTP. Le poste client, qui ne prend à sa
charge que la présentation et les contrôles de saisie,
s'est trouvé ainsi soulagé et plus simple à gérer.
Par contre, le serveur
HTTP constitue la pierre angulaire de l'architecture et
se trouve souvent fortement sollicité et il est
difficile de répartir la charge entre client et serveur.
On se retrouve confronté aux épineux problèmes de
dimensionnement serveur et de gestion de la montée en
charge rappelant l'époque des mainframes.
De plus, les solutions
mises en oeuvre sont relativement complexes à maintenir
et la gestion des sessions est compliquée.
Les contraintes
semblent inversées par rapport à celles rencontrées avec
les architectures deux tiers : le client est soulagé,
mais le serveur est fortement sollicité. Le phénoméne
fait penser à un retour de balancier.
Le juste équilibrage de
la charge entre client et serveur semble atteint avec la
génération suivante : les architectures n-tiers.
|